本文共 1685 字,大约阅读时间需要 5 分钟。
论文导读
相比于信息抽取,阅读理解任务要求机器能够整合篇幅较长的上下文信息(如整篇文章)并能够对事件进行推理。但是现阶段的阅读理解任务仍然能够以一种投机取巧的方法,利用浅层的语言形态学信息(如问答对之间的文本相似性以及整个文章内的统计词频)从问题中直接找到关于答案的蛛丝马迹。
因此文中提出了一个新的阅读理解数据集,旨在迫使机器必须通篇阅读书籍或者电影脚本(远远长于一篇文章)才能回答问题。该数据集更侧重于发掘机器阅读理解对于含蓄的叙述的理解能力而不是基于浅层的模式匹配就能够直接得到答案。
工作动机
人在阅读的时候往往通读全篇,并不一定能够记住书中的每一点细节,但是一定能够注意到书中有哪些关键的实体,并且记住这些实体的关系是怎么样的。
但是,现在的阅读理解任务的 benchmark 数据集并不能够针对这点进行测评,相反,多数问题可以通过 question 和 paragraph 之间的 pattern match 得到答案。
因此 DeepMind 提出了这个新的数据集 NarrativeQA,机器需要面对的是一整部书籍或电影剧本,在没有限定答案范围的前提下,机器需要从文本中找到最相关的段落并且总结出问题的答案。该任务十分具有挑战性。
那么,这个新的数据集理论上应该具备以下特征:
![]() 数据量需要控制在对于当前既有的模型来说十分困难,但仍处在人可以解决的范围内。
数据量需要控制在对于当前既有的模型来说十分困难,但仍处在人可以解决的范围内。
相关工作
主要提一下三个,SQuAD,MS MARCO 和 SearchQA。
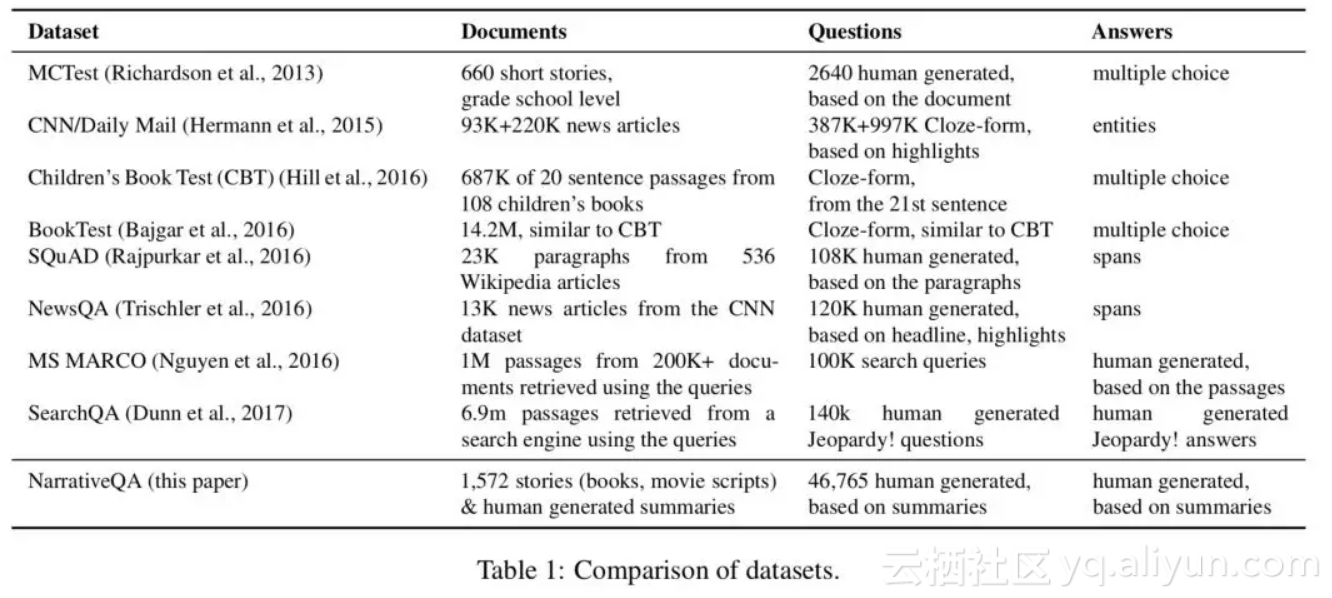
SQuAD 的场景比较局限,给定的来源于维基百科短文本,众包标注的问题以及从短文本中直接截取的答案。 MS MARCO 提出了更开放的数据集,文本来自搜索引擎,真实的用户问题以及众包标注的答案,但是多数答案仍然不可避免的是文本中的原文,多数在 SQuAD 测评中取得不错成绩的模型在 MS MARCO 上仍然能够取得不俗的结果。SearchQA 的文本来自搜素引擎,问题来自 Jeopardy,对,就是当年 Watson 一战成名的那个节目,然后统计发现,数据集中 80% 的答案少于两个单词,99% 的答案少于 5 个单词,抽样调查发现 72% 的问题答案是命名实体。论文作者似乎对这种很不屑,但我想说命名实体是我们这些知识图谱人的心头爱啊。
数据集分析
数据集的问答对中主要会出现 Title,Question,Answer,Summary snippet,Story snippet 等字段,其中 title 确定了问答对的出处,即围绕着哪本书或剧本来进行阅读。其中相关片段由人工标注得出,但并不建议在训练中作为标注语料使用,且最终的测试集中不会出现该类片段,需要程序自行设计文本段落的定位方案。
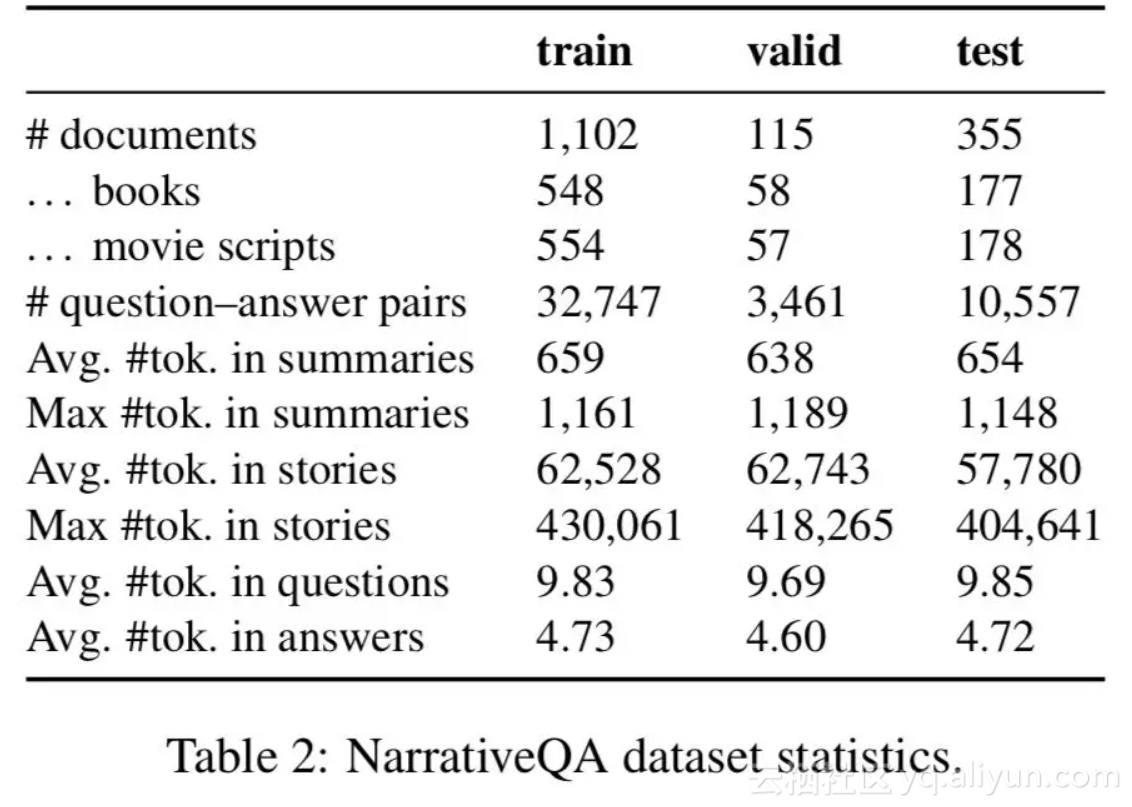
数据集的主体是小说以及电影剧本,问答集主要根据小说或电影的摘要信息进行提问,如果问答集同时提供了摘要,那么和现在的阅读理解任务也就没有什么不同了,但是,在没有提供摘要及标明相关段落的基础上,回答此类问题需要程序通读整部书籍,整理分析所有相关段落以进行阅读理解。
任务
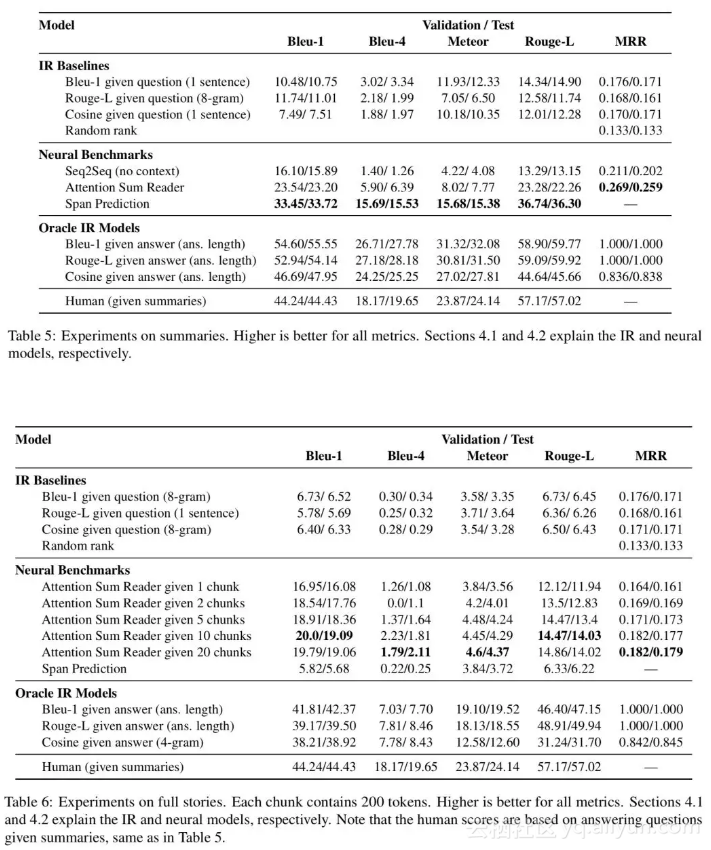
提供一组测试任务:分别以摘要和全文作为 context,测试基于答案生成和答案选择的两类阅读理解问题。测试指标包括 Bleu-1,Bleu-4,Rouge—L 以及基于答案排序的 MRR。
Baseline实验结果
文中提出了三类对比,一将其视为 IR 任务,二直接应用 LSTM 预测后缀词,三在全书范围内 IR+BiDAF。 最终的实验结果证明在全书范围内的阅读理解任务上,暂没有算法能够取得很好的结果。
转载地址:http://czbsx.baihongyu.com/